Duplicate posts for pro users
During yesterday and parts of today, some pro users have been seeing a lot of duplicate posts appearing. This is of course very regrettable and we believe we have fixed the issue.

To understand why this happened I must first describe the feeder pro infrastructure.
Our infrastructure
Free
Our product is separated into two tiers, “free” and “pro”. The free product was our initial product that I started working on all the way back in Chrome version 5, in 2010. It was a simple RSS extension for Chrome only. It was using simple HTML, CSS and JavaScript. Everything was stored locally in a WebSQL database inside the Chrome extension.
In 2012 we released a Safari extension with pretty much the same codebase. Everything was stored locally in a WebSQL database. If you wanted to sync between computers you would need to export your feeds as an OPML file and import in the destination browser.
Pro
Come 2012, me and my twin brother Johan decided to quit our consulting day jobs and work at home full time from our parents guest room. There we started rewriting feeder from the ground up, with a fresh design and fresh codebase. This time with Google Reader sync built in from the beginning.
At this point we did very little monetisation. We had a big “Please donate” button that a lot of really great people used. It helped us get inspired to work even harder on the product. However, this was not ideal, and also the thought of being locked into something like Google Reader was not ideal for us either. We wanted something that we could control, and we could build upon and improve on our own rules.
So one Friday night in my parents guest room I started looking into using Ruby on Rails as a frontend for a “WebSQL” emulator, that could seamlessly hook into our custom built ORM that used WebSQL and JavaScript. This became the foundation of the backend service for pro. What it basically does is map ORM calls to our API and into MySQL queries that could store in a backend database.
A couple of months later this product was pretty much ready to go. I had jumped onto a full time employment but was trying my hardest to work nights and weekends with the Pro product. Then Google Reader announced their closing, which forced us to work even harder to have something to replace for our users.
Upon release it went pretty well. Users had some issues and we learned a lot on the way. For example, be very transparent about where your users can contact you! Our first 5 transactions became PayPal disputes because our product did not meet the user’s demands, and we did not have a support e-mail setup.
After gaining some momentum, the pressure just got too much for our simple Ruby on Rails app, with a basic Node.js feed crawler and one MySQL server all on the same VPS.
Scaling pro
This was pretty much my first real scaling challenge, and it was really tuff trying to time keeping the servers up, with a full time job. I remember many times sitting on the buss to work with iSSH up on my phone trying to understand what went wrong, scaling up servers and just generally panicking.
The hardest challenge was to not let the feed crawling service crash our main database. It caused very heavy load due to crawling feeds every 10 minutes. This was to try and match our user’s demands for a really fast feed crawl time (minimum for free is 1 minute, which does local checks for new posts).
Uniqueness
The problem is that every feed is basically and XML file with a list of posts, that in some way make them unique. A well formed feed has a unique identifier included for each post, in what’s often called “GUID”. A lot of feeds do not include this, and it varies a lot between feeds what they do include. As a rule, a post is a link and a title. If less than that, it’s hardly a post. Another useful data point is usually a `created at` timestamp.
Using the post link for uniqueness turned out to not work very well. Many feeds added timestamps to the links, tracking tags unique for the user or other silliness. So we disregarded that entirely.
With the remaining datapoints we needed to form something that can easily be checked up. Initially, and stupidly, the crawling service actually did several MySQL query for each post in a feed file. Note that this was done for on average 20 posts per feed, in 1000 feeds, every 10 minutes. Some of these queries did not even hit an index. It might have looked something like:
SELECT COUNT(*) FROM posts WHERE title = ? AND created_at BETWEEN ? - 5 SECONDS AND ? + 5 SECONDS
Not good for our 20 USD per month VPS.
To combat this we created an MD5 hash for each post, consisting of $feed_id, $post_title, created at timestamp (if present) rounded down to the nearest 10 seconds. If a GUID was present for the post, use that instead. This turned our query into:
SELECT COUNT(*) FROM posts WHERE guid = ?
Better, and it hit an index we created. However, it still hit our MySQL database a lot for our increasing number of feeds.
Redis to the rescue
At the time Redis was very talked about, and caught my attention. It had an amazing amount of datastructures and seemed very robust. After some very basic benchmarking I found the Set. A “set” is basically a container with guaranteed unique values that is O(1) complexity of checking if something exists in that container. This suited perfectly with our needs, so that’s what we did. One huge set called “guids” that contained every single guid in for each post in each database.
This set grew and grew and grew. Then it crashed. That single datastructure consumed so much of our servers RAM that it crashed redis, and every other process on the server. It was also extremely important for us though. If we lost that data, we would have to rebuild that redis database from our also growing MySQL database. I have attempted to do this a long into some panicky nights, and it would take many days from my attempts.
The best way to scale all this up has been to separate each component out into a separate server, so that it can’t down everything with it if it ever crashes. To keep it very short, here is a simple diagram of how the feeder pro service is set up:
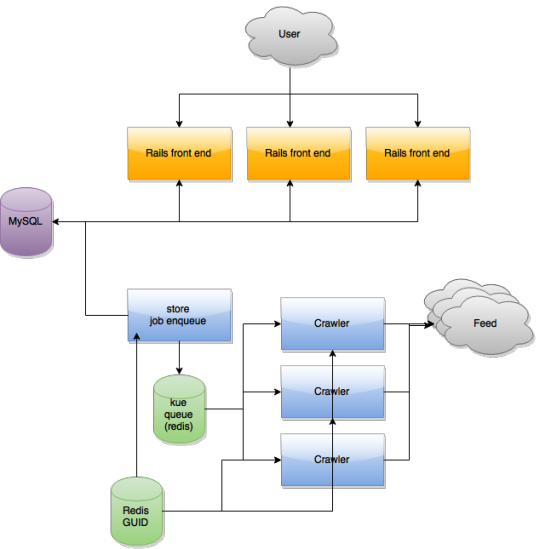
What happened
Yesterday
Yesterday, I started getting constant e-mails that our crawler servers were crashing. (Note, no e-mails about duplicate posts) This usually happens if they themselves run out of RAM (can happen with node memory leaks) or the hard drive is full (excessive logging and no log rotation set up). Other times it’s that our kue job queue has filled up because of too many feeds in the backlog and the kue server crashing because of no RAM left (kue uses redis for storage). It’s often times a quick fix. Restarting a service, clearing the job queue, etc.
Yesterday it wasn’t as simple. After some searching of the usual suspects I tried to SSH’d onto our GUID database redis server. It timed out. Linode has a service they call Lish, which let’s you SSH into a server as if you had connected a screen to that specific machine. That worked! I checked around on the server. Redis was running and and no data loss, RAM was was abundant.
However, I could not ping anything. `ping google.com` failed. Weirdly enough `ping 8.8.8.8` (Google’s DNS servers) worked fine. I recall having issues some while back with Linodes private networking and setting up DNS servers. This issue had popped up a couple of times so I remember something about doing weird quick fixes to get it running. I could not for the life of me remember what I did to get DNS working. After a reboot the `ping google.com` started working again and all was well. Not.
15 minutes later everything had crashed again and that server could not connect to anything anymore. I tried googling the problem but just couldn’t find anything about why Ubuntu would forget how to use DNS servers. That specific server was running Ubuntu 12, and a quick fix was to just `do-release-upgrade` and hope it solved the issue. It did! Everything was fine! I could go about my vacationing.
Today
Then today I started getting e-mails from users about duplicate posts. I stupidly assumed that this might have happened when the redis database server was upgrading and some stray crawling processes tried to check for new posts and got mixed up. I responded saying that we had experienced server troubles but that the issue was fixed yesterday.
During the day I continued to get these e-mails, and many of the users that I told the issue was resolved to came back saying “uuuhm, no”. As I was out in the world vacationing in Småland I could not check this ASAP and mentally pushed it to the back of my mind.
When I got back I logged on to all the servers and checked around and couldn’t see anything weird. What would cause duplicate posts? I checked error logs and process logs and nothing was acting weird. Something that did catch my eye on the redis database server was this in the redis.log:
[3232] 08 Aug 11:35:36.040 # Can’t save in background: fork: Cannot allocate memory
[3232] 08 Aug 11:35:42.051 * 1 changes in 900 seconds. Saving…
[3232] 08 Aug 11:35:42.052 # Can’t save in background: fork: Cannot allocate memory
[3232] 08 Aug 11:35:48.061 * 1 changes in 900 seconds. Saving…
[3232] 08 Aug 11:35:48.062 # Can’t save in background: fork: Cannot allocate memory
Aha! This I did recognise. Redis is an in-memory database, but it stores the contents of the database onto disk at regular intervals. To store onto disk it forks itself and creates a copy of the database (Copy on Write style, if I’m not mistaken). That puts some requirements on RAM though: If the redis database is 500 mb, redis needs a total of 1000 mb on the server. Redis is actually helpful enough to let you know that this is a problem in the logs, and recommends a solution.
If it can’t background save and redis crashes you lose all your changes. This is probably what had been happening during the day. Redis crashed because it could not background save, causing duplicate posts when redis restarted with a stale copy of the database.
Linux has a switch called overcommit_memory which I’m not entirely sure what it does, but my guess is that it lets a process overcommit the amount of memory it asks for, and simply falls back to Swap space if needed. By default this switch is off.
Enabling this is as simple as putting vm.overcommit_memory = 1 in the /etc/sysctl.conf file. My server install scripts does this automatically, so it’s rarely an issue. But! During the “do_release_upgrade” yesterday I recall Ubuntu kindly asking if I wanted to replace my `sysctl.conf` with the Ubuntus latest version. As I was in a hurry I just accepted it and continued.
How we fixed it
The fix was simple, run:
echo 1 > /proc/sys/vm/overcommit_memory
And also amend sysctl.conf.
Checking the logs they happily reported:
[3232] 08 Aug 11:35:48.062 # Can’t save in background: fork: Cannot allocate memory
[3232] 08 Aug 11:35:54.073 * 1 changes in 900 seconds. Saving…
[3232] 08 Aug 11:35:54.118 * Background saving started by pid 8486
[8486] 08 Aug 11:36:28.658 * DB saved on disk
[8486] 08 Aug 11:36:28.691 * RDB: 2 MB of memory used by copy-on-write
[3232] 08 Aug 11:36:28.768 * Background saving terminated with success
Why we can’t delete them easily
Our current post database is more than 500 GB, which includes post titles, links, guids and also post contents. This has presented a pretty massive scaling challenge, but to keep it short: We store posts in a “key-value”-store database and just pass around ID’s for unread posts, starred posts and also ordering of posts in feeds.
To be able to remove duplicate posts we also need to be able to detect duplicates. This would require a massive scan of our post database (which is not indexed by “created at”) and then also a scan of our ID index tables, removing them from the unread/starred/feed lists.
If you are affected by these duplicate posts and you really need us to delete them, it’s much easier to do on a per user/per feed basis. Therefor we ask if you have any issues or comments, please contact:
support@feeder.co